Kotlin is a powerful programming language targeting the Java platform that is quickly gaining traction amongst Android developers, holding fourth place among the fastest-growing programming language on several renowned indices. Known for its concise code, structured concurrency, enhanced security features, and 100% interoperability, Kotlin is approximately 20% less verbose than Java, making it an attractive choice for developers. Companies such as Pinterest, Uber, Trello, and Amazon have already adopted Kotlin for their projects.
In addition to being a multi-paradigm language, Kotlin is also a statically-typed language, allowing developers to write codes that are both safe, secure, and highly efficient.
In this post, we will explore some of the syntax and patterns of the Kotlin programming language, giving you a taste of the language and functional programming.
Functional Programming Quick Overview
Although the Functional Programming paradigm has only recently gained widespread adoption, it was the first programming paradigm to be invented. The development of Functional Programming is a direct result of Alonzo Church’s groundbreaking work on lambda calculus – a formal system in mathematical logic that was first introduced in the 1930s. Church developed l-calculus while attempting to solve the same mathematical conundrum that Alan Turing was attempting to solve at the same time.
A key tenet of l-calculus is the concept of immutability, where the values of symbols remain constant. Additionally, both Functional Programming and l-calculus utilize higher-order functions – functions that are either used as inputs or returned as outputs from other functions.
Functional programming is based on a simple premise: constructing programs using only pure functions.
A pure function is a function that is free of side effects and always produces the same output given the same input. This means that it does not rely on and/or modify any external state and does not interact with any external components. It also implies that the function does not cause any observable changes in the global state of the application. The output of a pure function should always be the same for any given input, regardless of how many times the function is invoked.
The concept of a pure function implies two key properties:
- that the function returns the same result for the same arguments,
- and that its application has no side effects.
In practice, these two rules discourage the use of imperative programming practices such as local static variables, non-local variables, and mutable references. Furthermore, these two principles also prohibit the use of input/output streams, since they are mutable and can produce different results and side effects with the same function call.
Functional Programming by Example
One of the best ways to showcase the difference between OOP to FB is demonstrating it by code. In the Clean Architecture book, Robert C. Martin uses a simple problem to demonstrate the differences:
Printing the squares of the first 25 integers.
In imperative style, using Java the program will look something like this:
In Clojure (declarative) which is a functional and dynamic dialect of Lisp, this might look as follow:
The Clojure syntax might look a bit strange at first, but once you get used to it, it makes sense.
The range function returns a never-ending list of integers starting from 0. This list passes into the map function, which calls an anonymous function with parameter x on each element, returning x * x. The list of squares passing into the take function returns a new list with only the first 25 elements. Finally, the println function prints its input, which is a list of squares of the first 25 integers.
Both of the functional programming properties are satisfied by the Clojure implementation as we don’t have any mutable variable, such as we have in the Java implementation the index variable i. Instead, in the Clojure program, we have a variable x that once initialized, is never modified.
This leads us to a surprising statement: Variables in functional languages
Robert C. Martin – Clean Architecture, Pearson Education, 2018, p. 73.do not vary.
Another thing to notice is that in the Clojure program, functions have a first-class citizen role, they don’t need to be warped by a class. Besides that, the (println) function takes other functions as arguments such as take and range, and take gets map as an argument which gets the anonymous inner function(fn[x](* x x)).
Kotlin and Functional Programming
One of the core assets of the Kotlin language design is to relax Java’s restriction of allowing static methods and variables to exist only within a class body. Instead, Kotlin functions can live at the top level of the package without needing a redundant class level.
Kotlin functions are first-class, which means they can be stored in variables and data structures, and can be passed as arguments to and returned from other higher-order functions. You can perform any operations on functions that are possible for other non-function values.
Kotlin documentation
Higher-order Functions and Lambdas

Kotlin has different syntax ways to pass anonymous functions and lambdas as a parameter:
This is probably the most basic implementation of lambdas in Kotlin, its syntax is very similar to a callback function. While callback functions can be either anonymous or named, lambdas are anonymous. In fact, lambdas are the functional way to implement callbacks.
Following is another example to point the difference between impertative and declartive programming:
Given two arrays of strings
Codewarsa1anda2return a sorted arrayrin lexicographical order of the strings ofa1which are substrings of strings ofa2.
Imperative – Procedural
Declarative – Functional
The imperative program is a function called inArray, which takes to arrays of strings as parameters. First, it initializes a variable r of an empty array, then it initializes inside the first for loop, the variable str. Next, the variable str1 inside the second for loop. Then, check if str1 contains str and if it does not exist yet on the initialized array r it adds add. Finally, it returns the sortedArray function value of r.
The declarative program executes the same algorithm but without mutable variables. Instead of looping with for and appending proper elements to r, the toTypedArray() function is called on the sorted() returned value which called on distinct() returned value which is called on the array1.filter result that is a collection of elements that passed the conditions of its lambda.
In terms of complexity, both implementations are running in quadratic time, but the benefits of the declarative implementation are avoiding possible race conditions, deadlock conditions and concurrent updates problems which are all related to mutable variables. You cannot have a race condition or a concurrent update problem if no variable is ever updated. You cannot have deadlocks without mutable locks.
Data Classes, Constructors and Methods
It is not unusual to create classes whose main purpose is to hold data. In such classes, some standard functionality and some utility functions are often mechanically derivable from the data. In Kotlin, these are called data classes and are marked with
Kotlinlang docsdata:
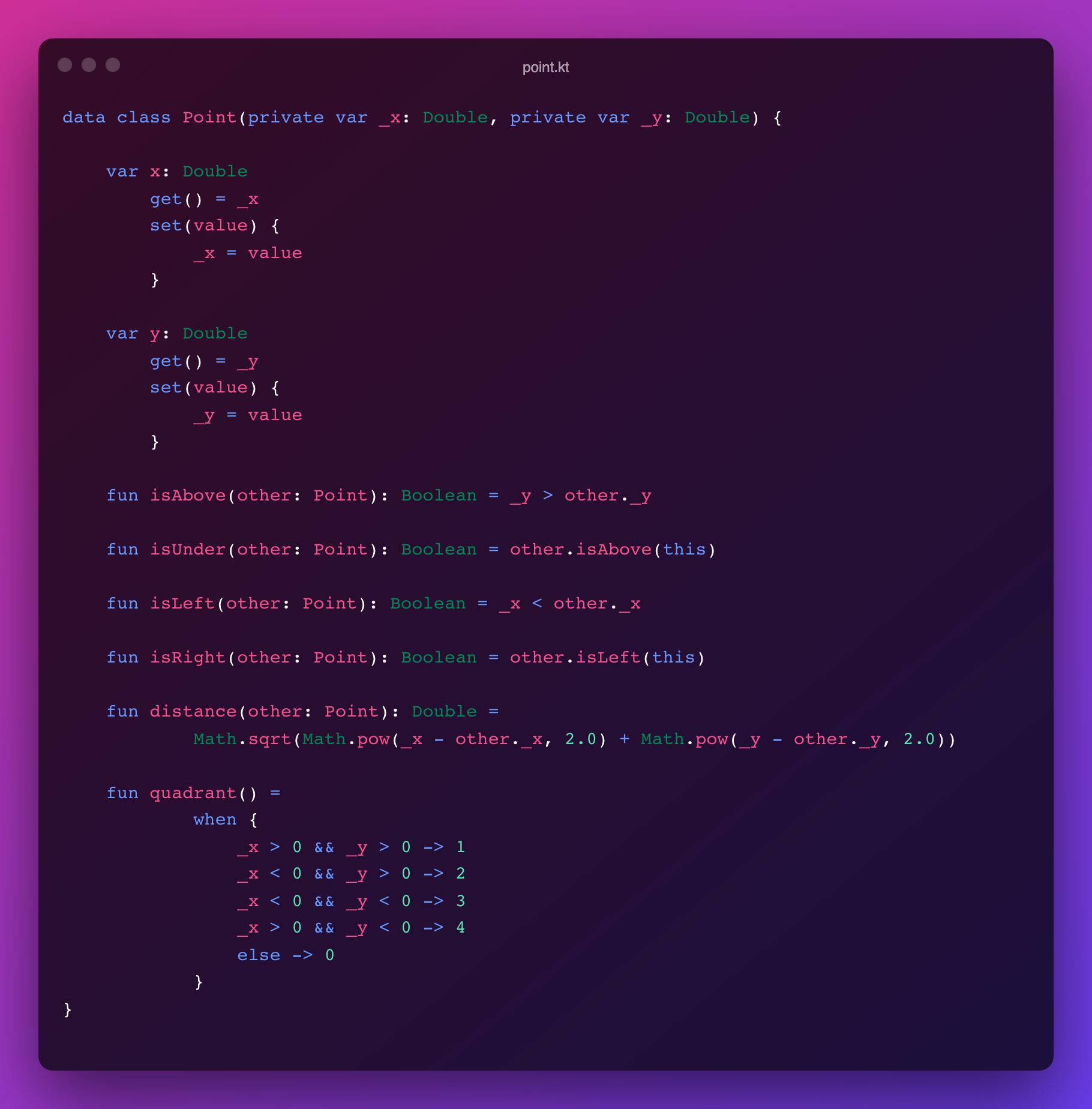
As already mentioned, this post is not a tutorial, but rather a high-level view of the Kotlin feature. To emphasize the Kotlin way of writing a class I’ll be using the Point class – a basic student task which goes as follows:
The Point class represents a 2-dimensional point in euclidean space and has the following properties:
- Private variables x and y of type double represent the coordinates of the point.
- A copy constructor.
- Get x – returns the x coordinate.
- Get y – returns the y coordinate.
- Set x – sets a new value for the x coordinate.
- Set y – sets a new value for the y coordinate.
- To string – returns a string representation of the point.
- Equals – takes another point as input and returns true if other equals to this, otherwise return false.
- Is above – takes another point as input and returns true if this point is above the other, otherwise returns false.
- Is under – dose the same as above but true if under and otherwise false.
- Is left – …
- Is right – …
- Distance – takes another point as input, and returns the distance between this point and other.
- Quadrant – returns the quadrant in which the point lies.
Implementing this using Java should look something like this:
The Kotlin implementation would look as follow:
Much shorter! isn’t it? and it does exactly the same things.
If you ask yourself where is the copying constructor or where are the toString and equals methods, so the Kotlin compiler automatically derives these class members for data classes.
Advantages of using Kotlin for Functional Programming
- Kotlin is a statically-typed language, which ensures that code runs more efficiently and reliably than code written in dynamic languages.
- Kotlin’s syntax is concise and easy to read, making it easier for developers to understand and maintain code.
- Kotlin offers many features that make it easier to write functional code, such as higher-order functions, data classes, and multiple return types.
- Kotlin provides a range of interoperability features, allowing developers to easily integrate existing Java code and libraries into their Kotlin projects.
Disadvantages of using Kotlin for Functional Programming
- Kotlin’s support for functional programming may not be as comprehensive as other languages, such as Haskell or Scala.
- While Kotlin compiles to Java bytecode, the performance of code written in Kotlin may not be as good as code written in Java. (Read more about it here)
- It can be difficult to debug functional code written in Kotlin due to its lack of debugging tools. (Read more about it here)